







A OpenAI divulgou nesta quinta-feira (25) os resultados de um novo benchmark, batizado de GDPval, que mede o desempenho de sistemas de inteligência artificial em comparação a trabalhadores humanos de diferentes áreas. O objetivo, segundo a empresa, é estimar o quão próximos os modelos estão de executar tarefas de alto valor econômico em nível semelhante ao de especialistas.
No levantamento, o GPT-5 e o Claude Opus 4.1 (da rival Anthropic) foram testados em 44 ocupações de nove setores estratégicos da economia dos Estados Unidos, como saúde, finanças, governo e manufatura. Profissionais experientes compararam relatórios produzidos por humanos e por IA — e, em parte das vezes, deram a vitória às máquinas.
++ Escultura de Trump e Epstein de mãos dadas aparece em frente ao Capitólio, em Washington
Resultados
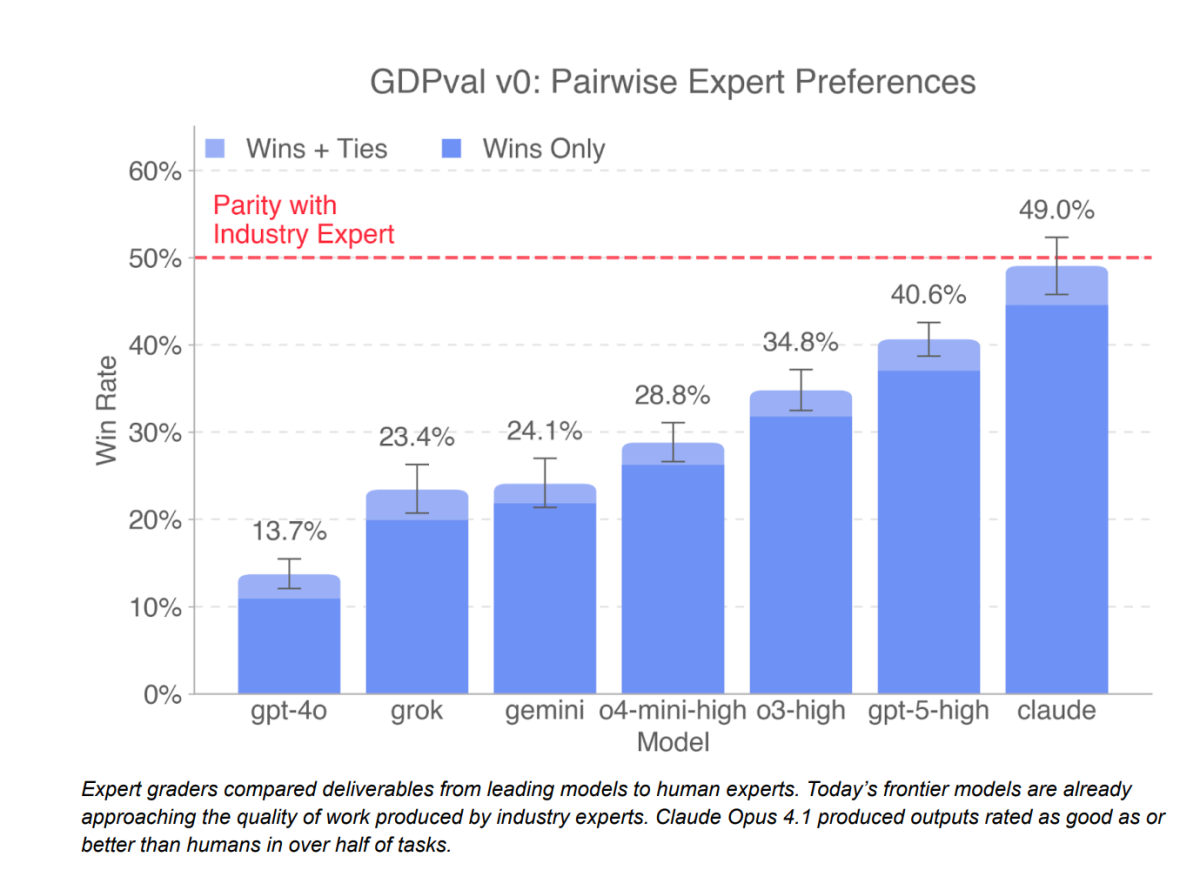
O GPT-5-high, versão mais potente do modelo, foi avaliado como igual ou superior ao trabalho humano em 40,6% das situações. Já o Claude se saiu melhor: foi considerado equivalente ou superior em 49% dos casos.
A OpenAI pondera que a vantagem do Claude pode estar relacionada ao estilo de saída mais “agradável”, com gráficos e apresentações bem formatadas, em vez de puro desempenho técnico. Mesmo assim, os números mostram um salto em relação ao GPT-4, que no mesmo tipo de teste havia alcançado apenas 13,7%.
Limitações
Apesar do avanço, a própria empresa admite que o GDPval-v0 cobre um escopo restrito, centrado em tarefas de elaboração de relatórios. Na vida real, lembram os analistas, o trabalho humano envolve muito mais do que escrever documentos — inclui interação, tomada de decisão em cenários ambíguos e habilidades práticas.
Ainda assim, a OpenAI vê progresso notável. “Esses resultados sugerem que profissionais podem usar os modelos de IA para otimizar seu tempo, delegando parte das tarefas e se dedicando a atividades de maior valor”, disse o economista-chefe da empresa, Aaron Chatterji.
++ Anvisa responde a Trump e nega risco do paracetamol na gestação
O que vem pela frente
A equipe já planeja versões futuras do benchmark para avaliar fluxos de trabalho mais amplos. A expectativa é que avaliações como o GDPval ganhem relevância, em um cenário onde outros benchmarks tradicionais (como o GPQA Diamond e o AIME) já estão saturados por diferentes modelos.
Enquanto isso, a disputa segue acirrada no Vale do Silício. Para além de métricas técnicas, o desafio das empresas é provar que seus modelos não apenas empatam em laboratório, mas podem de fato superar humanos em tarefas reais do mercado — e com consistência.

{kind=link}